L'apprentissage par renforcement interne : une avancée pour les modèles autoregressifs
J'explore comment l'apprentissage par renforcement interne repousse les limites des modèles autoregressifs face aux récompenses rares.
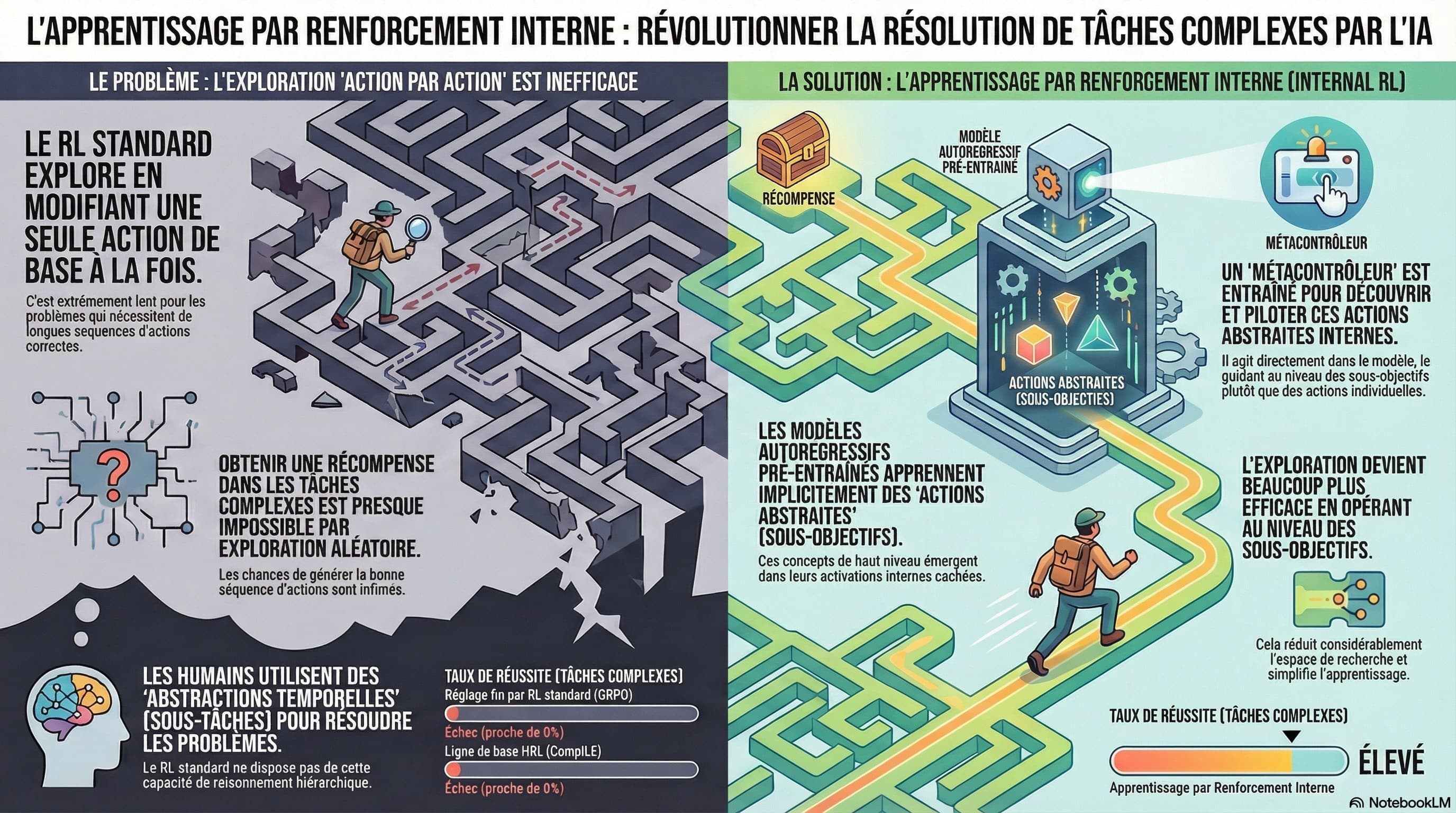
J'ai récemment découvert que les modèles autoregressifs, lorsqu'ils sont optimisés avec l'apprentissage par renforcement, ouvrent de nouvelles perspectives dans différents domaines. Ces modèles proposent de nouvelles solutions en générant des séquences un token à la fois. Mais une des limites que j'ai constatées se manifeste lors des cas de récompenses rares, rendant cette méthode inefficace.
Exploration interne et actions abstraites
Pour contourner ce problème, mon exploration s'est concentrée sur les représentations internes des modèles autoregressifs. En intégrant un modèle de séquence non causal à haut niveau, j'ai réussi à contrôler les actions abstraites temporelles à l'intérieur du flux d'activations résiduelles du modèle de base.
Ce modèle de haut niveau, dans des tâches hiérarchiquement structurées, parvient à comprimer les séquences d'activation en contrôleurs internes, capables d'exécuter des actions significatives sur des périodes prolongées grâce à une condition de terminaison apprise.
La génération d'actions latentes renforcée permet à un modèle autoregressif de réussir là où les approches traditionnelles échouent.
Résultats et architecture
J'ai observé que les prévisionnistes d'actions développent naturellement des représentations d'actions abstraites. Ces représentations, contrôlables linéairement, ont conduit à une nouvelle architecture neuronale pour le contrôle des modèles autoregressifs.
Une architecture neuronale innovante
Cette architecture s'appuie sur un métacontrôleur formé en auto-supervision pour générer des contrôleurs internes d'actions abstraites. Elle fonctionne sans signal de supervision et utilise des échanges avec le flux résiduel d'un modèle préentrainé ainsi qu'une condition future durant l'apprentissage. Ainsi, le métacontrôleur devient non causal, influencé par une séquence intégrée analysée a priori.
L'apprentissage par renforcement interne
La proposition d'un paradigme d'« apprentissage par renforcement interne » propose une alternative bien plus rapide que le réglage fin traditionnel, notamment dans les tâches structurées hiérarchiquement. En intégrant cette approche dans le flux résiduel du modèle principal, où les activations internes deviennent observations et les sorties du métacontrôleur des actions, le succès s'atteint plus efficacement dans les tâches complexes.
Les résultats obtenus démontrent les avantages de l'apprentissage par renforcement interne, permettant aux modèles autoregressifs de gérer des tâches de récompense rare là où d'autres techniques échouent.

